-
requests와 beautifulsoup 라이브러리Crawling 2022. 7. 17. 15:42
requests란 ?
HTTP 통신을 위한 파이썬 라이브러리입니다.
터미널에 pip install requests 명령어를 입력해 설치해줍니다.
requests의 기본 사용법

먼저 requests 라이브러리를 불러옵니다
.
get 함수를 사용하여 원하는 특정 사이트의 주소를 입력해
requests(요청)하여 response(응답)을 받습니다..text 안에 사이트의 html 코드가 들어있습니다.
BeautifulSoup란?
HTML 분석을 위한 파이썬 라이브러리 입니다.
터미널에 pip install beautifulsoup4 명령어를 입력해 설치해 줍니다.
BeautifulSoup 기본 사용법
- '네이버를 시작페이지로' 버튼 크롤링
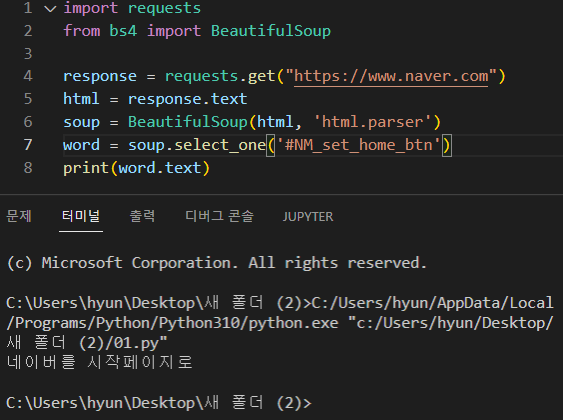
Beautifulsoup(html 코드, html 번역선생님)
HTML 파일로 BeuatifulSoup 객체를 만듭니다.
변수 이름은 관습적으로 soup라고 짓습니다.
html.parser는 파이썬 내장클래스로
BeautifulSoup 객체에게 HTML을 분석하라고 알려주는 것입니다.
soup를 이용해 내가 원하는 태그를 선택할수 있습니다.select는 여러개의 태그를 선택하고 싶을 때
select_one은 한개의 태그를 선택하고 싶을 때 사용합니다.
네이버 페이지에서 F12를 눌러 크롬 개발자 도구를 열어줍니다.
1. 을 클릭한 다음
2. 원하는 텍스트(네이버를 시작페이지로)를 눌러 주면 해당 내용으로 바로 찾아가집니다.
3. id(고유한 이름값)값을 .select_one()에 입력해 줍니다.
(*** id값은 앞에 #을 붙여줘야 합니다.)
.text를 이용해
선택한 태그에 대한 텍스트 요소만 출력할 수 있습니다.출처 : 파이썬 크롤링 기초 강좌